二分类问题:理解、应用与实战
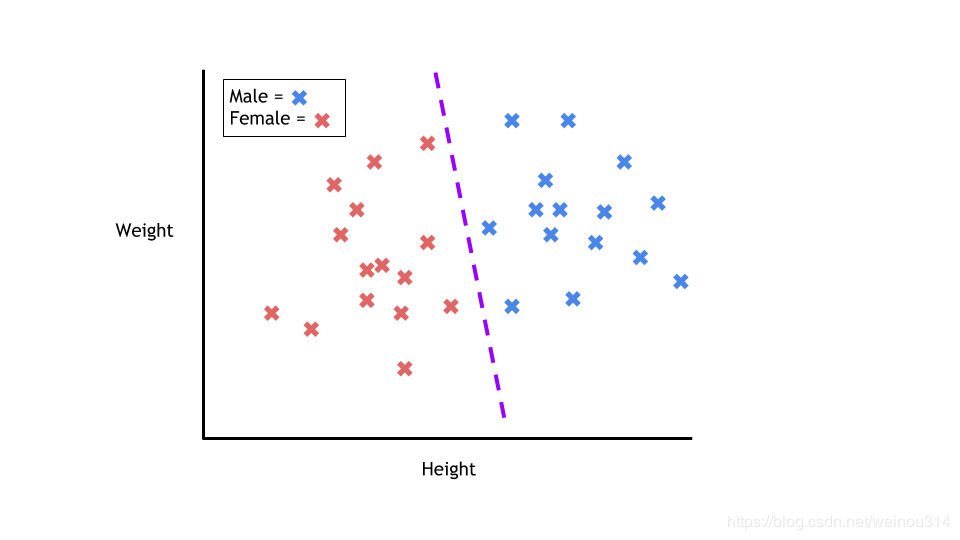
在机器学习领域,二分类问题是一种常见的任务。这种问题在现实场景中具有广泛的用途,例如垃圾邮件的识别、疾病的诊断等。本篇文章将探讨二分类问题的基本概念、应用场景以及如何通过编程进行实际应用。
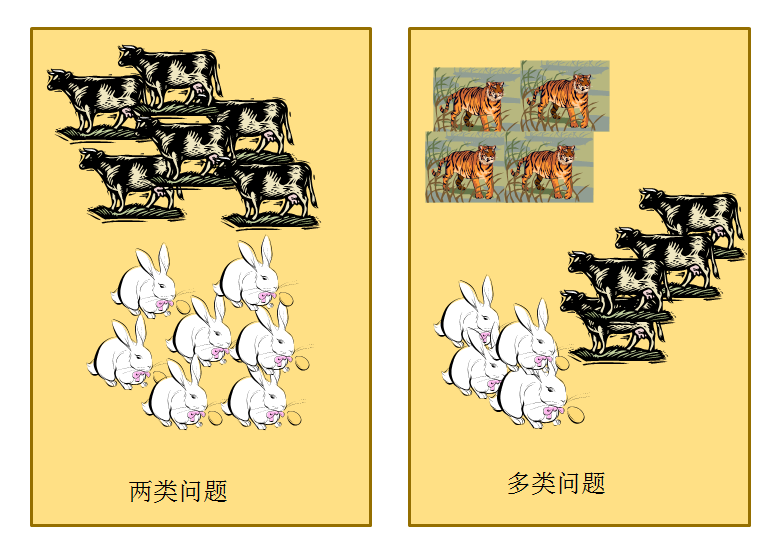
一、二分类问题的基本概念
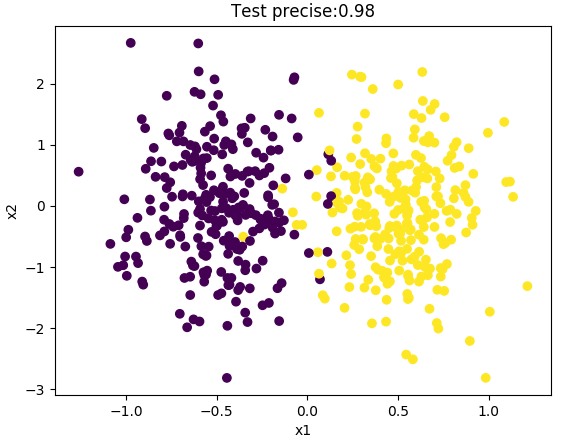
二分类问题是一种监督学习任务,它通过已知的输入和输出数据集来训练模型,从而能够根据新的输入预测出其对应的输出类别。这种输出通常为两种不同的类别,如真/假、是/否等。
二、二分类问题的应用场景
- 垃圾邮件识别:通过分析邮件的文本内容、发件人等特征,判断该邮件是否为垃圾邮件。
- 疾病诊断:根据病人的症状、体征等信息,判断其是否患有某种疾病。
- 图像识别:在图像中识别出特定的物体或人物等,如猫狗分类、人脸识别等。
三、如何使用二分类模型
首先,需要收集一定数量的带标签的样本数据。接着,通过合适的机器学习算法训练模型,最后用测试集对模型进行测试和验证。以下是二分类问题的编程步骤:
- 数据预处理:对数据进行清洗、格式化等操作,使其适合用于机器学习算法。
- 特征提取:从原始数据中提取出有用的特征,以便用于训练模型。
- 模型选择与训练:选择合适的机器学习算法(如逻辑回归、决策树等),使用训练集对模型进行训练。
- 模型评估与优化:使用测试集对模型进行评估,根据评估结果进行模型优化。
- 模型应用:将训练好的模型应用于新的数据上,进行预测和分类。
四、实战案例
以垃圾邮件识别为例,我们可以使用Python的scikit-learn库进行编程实现。首先收集一定数量的邮件样本数据,包括文本内容、发件人等信息以及对应的标签(是否为垃圾邮件)。然后进行数据预处理和特征提取,选择合适的机器学习算法(如朴素贝叶斯、支持向量机等)进行训练和测试。最后,将训练好的模型应用于新的邮件上,进行垃圾邮件的分类和识别。
总之,二分类问题是机器学习中常见的任务之一,其应用广泛且实用性强。通过对数据的理解和处理以及选择合适的机器学习算法,我们可以有效地解决各种二分类问题。



















