网络爬虫是什么?

一、引言
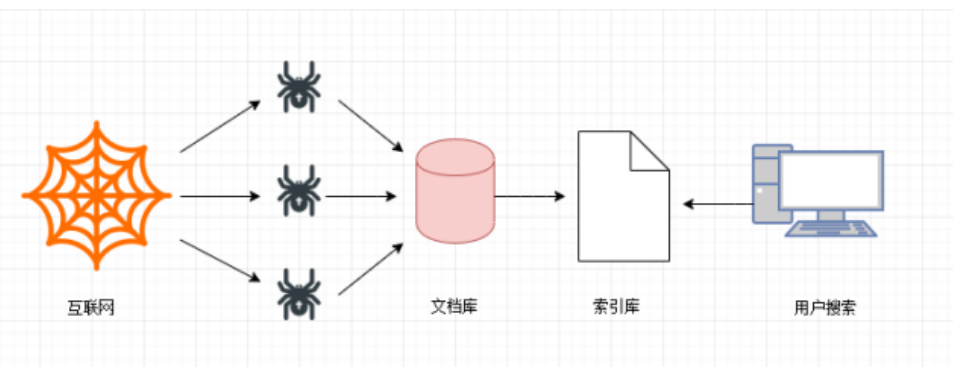
在当今的互联网时代,信息量巨大且繁杂。为了更高效地获取、整合及利用这些信息,人们发展出了许多工具和手段。其中,网络爬虫就是一个被广泛应用的工具。本文将带你一探究竟,网络爬虫究竟是什么。

二、网络爬虫的基本定义
网络爬虫,又被称为网络蜘蛛、网络机器人等,是一种自动抓取互联网信息的程序。它按照一定的规则,自动地访问互联网上的网页并提取有用的信息。
三、网络爬虫的工作原理
-
设定目标:首先,你需要明确你想要爬取什么样的信息。比如你想获取某个网站上的所有商品信息。
-
发送请求:网络爬虫向目标网站发送请求,请求该网站的数据。
-
获取响应:网站服务器接收到请求后,会返回相应的数据。这些数据可能是HTML页面、JSON数据等。
-
解析数据:网络爬虫需要解析这些数据,提取出你感兴趣的信息。这通常需要使用一些解析工具或库,如BeautifulSoup等。
-
存储数据:提取完信息后,你需要将这些数据存储起来,以便后续使用。这可以存储在数据库中、文件中或直接用于其他程序。
四、网络爬虫的应用场景
-
数据挖掘:从各大网站上获取各种类型的数据,用于数据分析、数据挖掘等任务。
-
搜索引擎:搜索引擎使用爬虫程序来收集互联网上的信息,然后建立索引供用户搜索。
-
学术研究:在学术研究中,爬取相关网站的数据可以帮助研究者进行数据分析、趋势预测等任务。
-
其他应用:此外,网络爬虫还可以用于监控竞争对手的网站、进行市场调查等任务。
五、总结
总的来说,网络爬虫是一种重要的互联网工具,它能够帮助我们快速、准确地获取、整合及利用互联网上的信息。但同时,我们在使用网络爬虫时也需要注意遵守相关法律法规及网站的访问协议,尊重他人的劳动成果和隐私权。
以上就是关于网络爬虫的基本介绍和其应用场景的简单介绍。希望这篇文章能让你对网络爬虫有一个初步的了解和认识。



















