一、文章标题
召回率
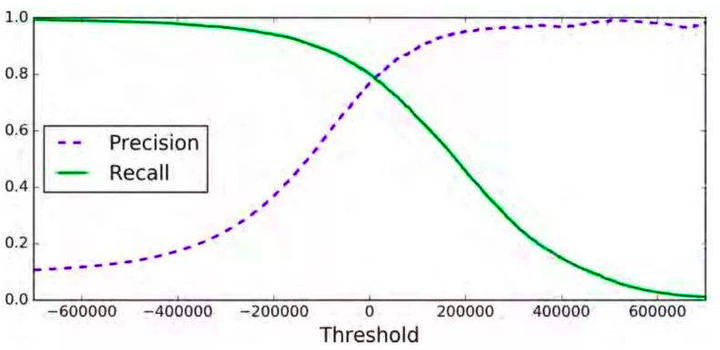
二、文章内容
在机器学习和数据挖掘领域,召回率是一个非常重要的评价指标。它通常用于衡量模型在分类任务中的性能,特别是在二分类问题中。本文将详细介绍召回率的定义、计算方法以及如何利用它来评估分类模型的性能。
一、召回率的定义
召回率,又称为查全率(True Positive Rate),用于评估正类样本被正确识别为正的比例。在二分类问题中,模型将数据划分为正类和负类,而召回率主要关注的是模型将正类样本正确识别为正的比例。
二、召回率的计算方法
召回率的计算需要用到混淆矩阵(Confusion Matrix)中的数据。混淆矩阵是一个二维表格,用于描述实际类别与模型预测类别之间的关系。在二分类问题中,混淆矩阵包含四个元素:真正例(True Positive)、假正例(False Positive)、真负例(True Negative)和假负例(False Negative)。
召回率的计算公式为:召回率 = 真正例 / (真正例 + 假负例)。这个公式的含义是,模型正确识别出的正类样本数除以所有实际为正类但被模型预测为负类的样本数加上模型正确识别出的正类样本数。因此,召回率越高,说明模型在正类样本上的识别能力越强。
三、如何利用召回率评估分类模型性能
召回率是评估分类模型性能的重要指标之一。在实际情况中,我们需要关注正类样本的识别情况,因为这些样本通常更加重要和有价值。通过计算召回率,我们可以了解模型在正类样本上的识别能力,从而对模型的性能进行评估。
除了召回率之外,我们还可以结合其他指标如精确率(Precision)、F1分数等来全面评估模型的性能。这些指标可以帮助我们更全面地了解模型在各个方面的表现,从而进行更准确的模型选择和优化。
四、总结
本文介绍了召回率的定义、计算方法以及如何利用它来评估分类模型的性能。在机器学习和数据挖掘领域中,通过合理使用召回率等评价指标,我们可以更好地了解模型的性能,并进行相应的优化和改进。希望本文能对大家有所帮助!



















