一、文章标题:文本聚类
二、文章内容
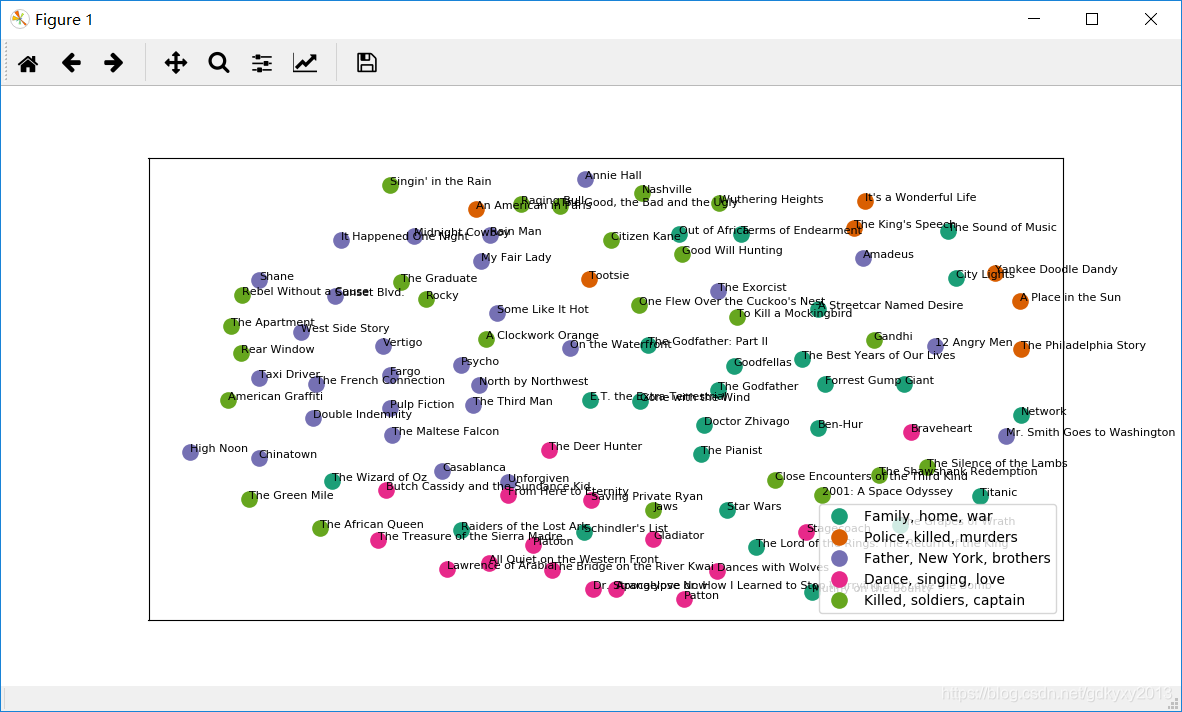
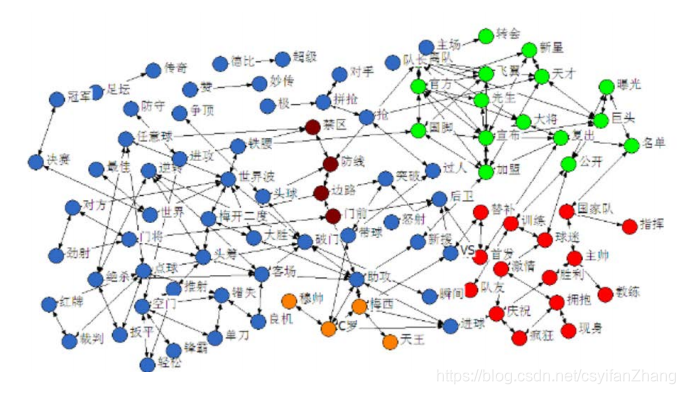
在当今信息爆炸的时代,文本数据大量涌现,如何从海量的文本信息中有效地提取和整理有价值的信息,成为了一个重要的研究课题。文本聚类作为一种无监督的机器学习方法,能够在海量文本数据中发掘潜在的类别信息,帮助我们更好地理解和利用这些数据。
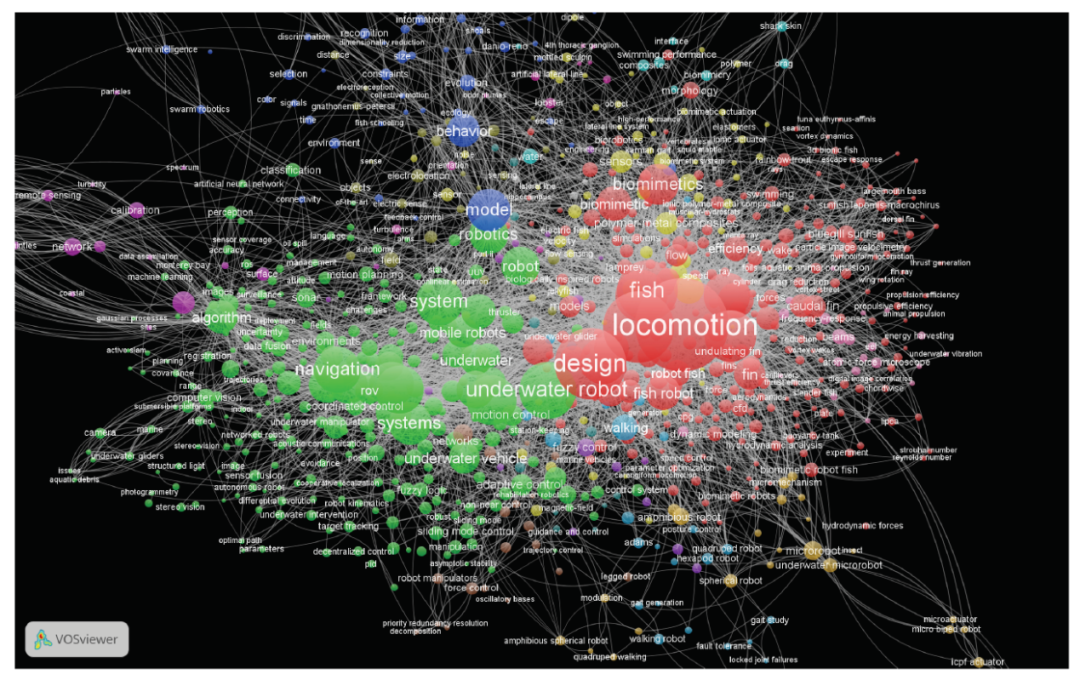
1. 文本聚类的基本概念
文本聚类,顾名思义,就是对文本数据进行分类的一种方法。它将相似的文本聚合成一个类别,从而帮助我们快速地找到某一主题下的相关文本。这种方法的核心思想是通过计算文本之间的相似度来将它们归为一类。
2. 文本聚类的基本步骤
(1)数据预处理:在聚类之前,需要对文本数据进行预处理,包括去除停用词、词干提取等步骤,以便更好地表示文本内容。
(2)特征提取:将预处理后的文本数据转化为机器可以识别的特征向量,例如通过TF-IDF算法或词向量算法进行特征提取。
(3)聚类算法:根据提取的特征向量,使用聚类算法对文本进行分类。常见的聚类算法包括K-means算法、层次聚类等。
(4)结果评估:通过计算各类别内文本的相似度以及不同类别之间的差异度来评估聚类结果的质量。
3. 文本聚类的应用场景
(1)新闻推荐:根据用户的阅读习惯和兴趣,通过文本聚类将新闻分为不同的主题类别,从而为用户推荐相关的新闻。
(2)社交网络分析:在社交网络上,通过文本聚类可以分析用户的兴趣爱好、社交关系等,从而更好地理解社交网络的结构和功能。
(3)学术论文检索:在学术论文检索中,通过文本聚类可以将相关的论文归为一类,方便研究者快速找到自己需要的文献资料。
总之,文本聚类是一种重要的文本挖掘技术,可以帮助我们从海量文本数据中提取和整理有价值的信息。随着机器学习和自然语言处理技术的不断发展,文本聚类的应用前景将会更加广阔。



















