一、文章标题
爬虫框架
二、文章内容
在互联网时代,数据获取的重要性不言而喻。爬虫框架作为数据获取的重要工具,是数据采集和处理的关键所在。本文将简要介绍爬虫框架的原理和构造,并分析其重要性和实际应用。
一、爬虫框架的原理和构造
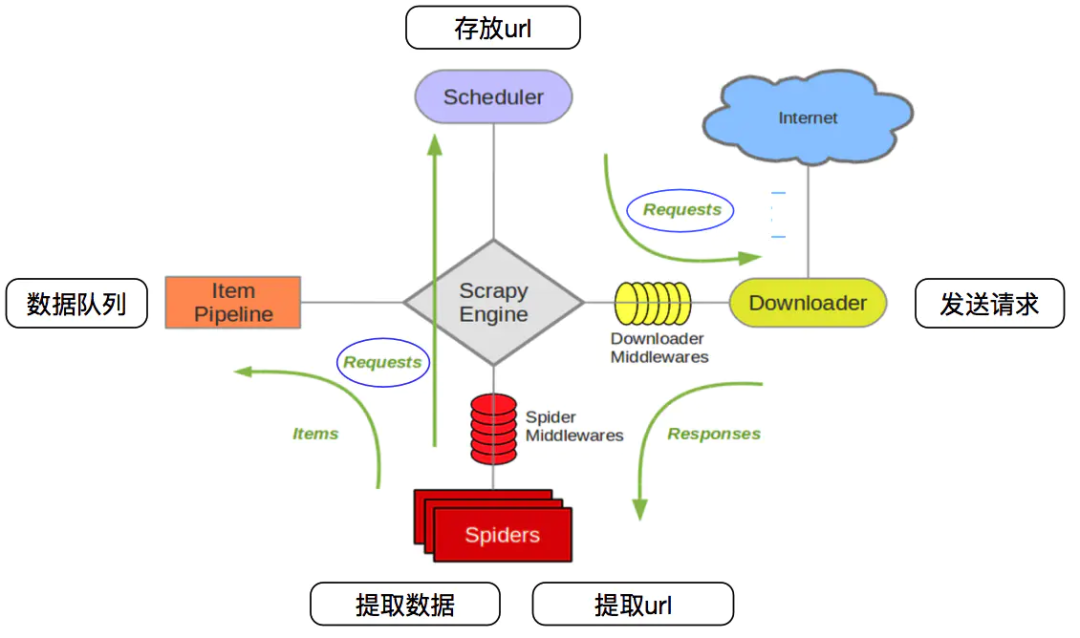
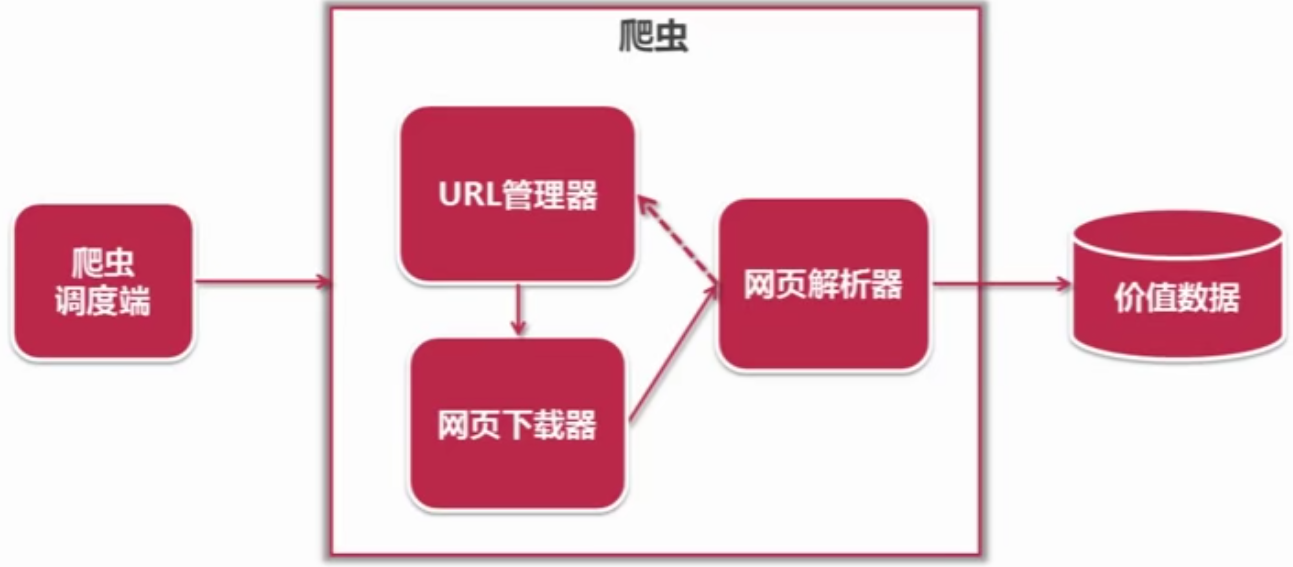
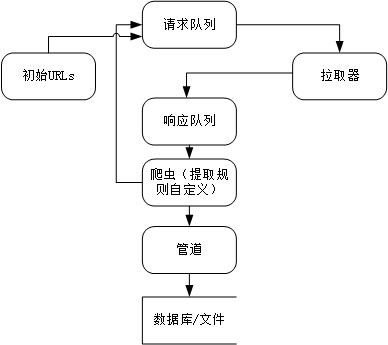
爬虫框架是一个程序结构,用于从互联网上抓取数据。它主要包括以下几个部分:
-
爬取器(Crawler):负责从互联网上抓取网页信息,包括网页的URL、标题、正文等。
-
调度器(Scheduler):负责管理待抓取的URL队列,按照一定的策略进行排序和调度。
-
解析器(Parser):负责对抓取到的网页进行解析,提取所需的数据信息。
-
数据存储(Data Store):负责将提取的数据进行存储和整合,以供后续使用。
在构造爬虫框架时,需要注意以下几个关键点:
(1)目标确定:明确要爬取的数据类型和目标网站。
(2)制定爬取策略:根据目标网站的结构和特点,制定合适的爬取策略,包括URL的获取、页面解析等。
(3)优化性能:优化爬虫框架的性能,包括提高抓取速度、降低内存消耗等。
二、爬虫框架的重要性
爬虫框架在数据获取和处理中扮演着重要的角色。它具有以下重要性:
(1)提高数据获取效率:通过爬虫框架,可以快速地从互联网上抓取大量数据,提高数据获取效率。
(2)降低人工成本:通过自动化地执行数据抓取任务,可以降低人工成本,提高工作效率。
(3)支持数据分析和挖掘:通过将抓取到的数据进行整合和存储,可以为后续的数据分析和挖掘提供支持。
三、实际应用
爬虫框架在实际应用中有着广泛的应用场景。例如,在电商领域中,可以通过爬虫框架抓取商品信息和价格数据,为电商平台的运营和决策提供支持;在新闻媒体领域中,可以通过爬虫框架抓取新闻信息,为新闻报道和编辑提供便利;在搜索引擎中,爬虫框架更是不可或缺的一部分,它能够自动地抓取互联网上的信息,为用户提供更加便捷的搜索体验。
总之,爬虫框架是数据获取和处理的重要工具,它具有广泛的应用场景和重要的意义。通过了解其原理和构造,我们可以更好地应用它来提高数据获取效率和工作效率。



















