一、文章标题:去重SQL
二、文章内容

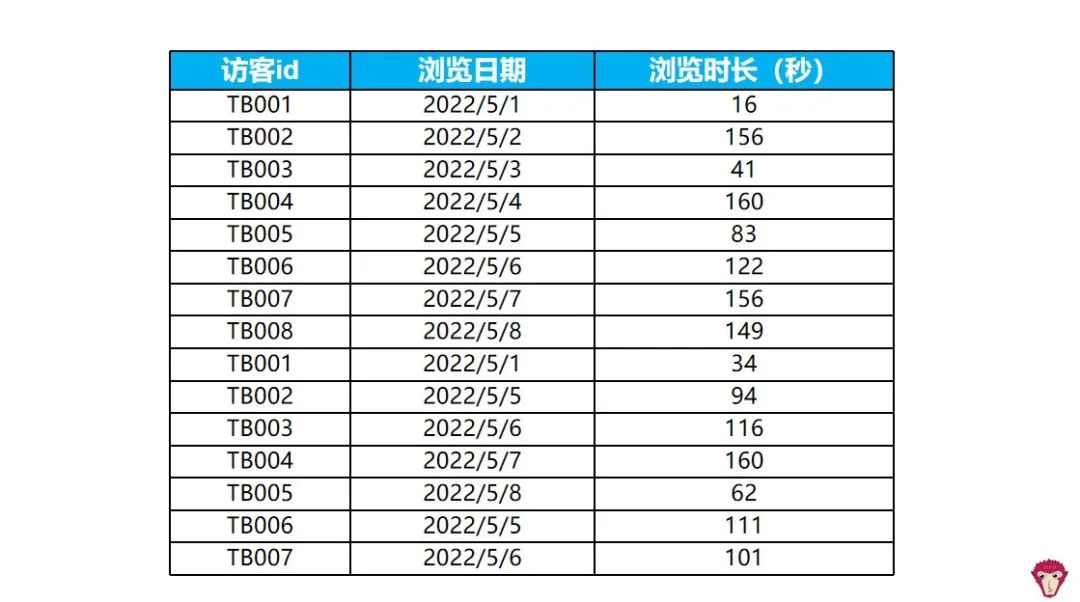
在数据库中处理重复数据是一个常见的任务,特别是在处理大量数据时。SQL语言提供了多种去重的方法,下面我们将详细介绍其中的一些方法。
- 使用
DISTINCT关键字
DISTINCT是SQL中用于去除查询结果中重复记录的关键字。它可以在SELECT语句中与其他列名一起使用,用于选择唯一的记录。例如:
SELECT DISTINCT column_name
FROM table_name;
这条SQL语句将返回table_name表中column_name列的唯一值,即去除重复后的结果。
- 使用
GROUP BY语句
GROUP BY语句通常与聚合函数一起使用,用于根据一个或多个列对结果集进行分组。它也可以用来去重。例如:
SELECT column_name, COUNT(*)
FROM table_name
GROUP BY column_name;
这条SQL语句将根据column_name列的值对结果进行分组,并计算每个分组的数量。由于每个分组只会出现一次,因此这也达到了去重的目的。
- 使用
NOT EXISTS子查询
NOT EXISTS子查询是一种常用的去重方法,它通过比较两个表或查询结果来去除重复记录。例如:
假设我们有两个表:table1和table2,我们想从table1中选择不与table2中任何记录重复的记录,可以使用以下SQL语句:
SELECT *
FROM table1 t1
WHERE NOT EXISTS (
SELECT 1
FROM table2 t2
WHERE t1.column_name = t2.column_name
);
这条SQL语句将返回在table1中存在但在table2中不存在的记录。通过调整子查询的条件,我们可以实现更复杂的去重需求。
- 使用窗口函数和ROW_NUMBER()
在某些情况下,我们可以使用窗口函数和ROW_NUMBER()等函数来为每条记录分配一个唯一的序号,然后根据这个序号进行去重操作。这种方法通常用于处理具有多列重复值的情况。例如:
假设我们有一个包含多列的表table3,我们想根据某些列的值对记录进行排序并去重,可以使用以下SQL语句:
首先,为每条记录分配一个唯一的序号:



















