文章标题:堆与栈的深度解析
一、概述
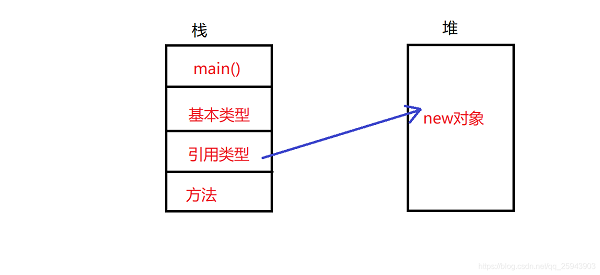
在计算机编程中,堆和栈是两个非常关键且常被提及的概念。它们都是内存管理的重要部分,但在使用和管理上有着显著的差异。本文将深入探讨堆和栈的定义、特性以及它们在编程中的应用。
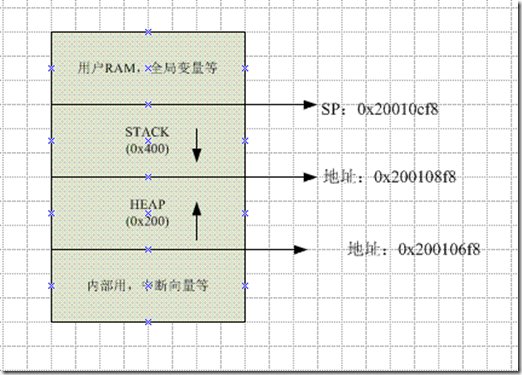
二、堆(Heap)
堆是用于动态内存分配的区域。与栈不同,堆内存的分配不需要预先分配空间,它可以在运行时根据需要动态地申请和释放。这种灵活性使得堆成为处理大量数据或未知数据量时的理想选择。在C/C++等语言中,我们常常使用malloc、free或new、delete等函数来操作堆内存。
特点:
- 动态分配:可以在运行时根据需要申请或释放内存。
- 不固定大小:堆内存的大小是动态变化的,取决于程序运行时的情况。
- 速度较慢:由于需要搜索可用内存,堆内存的分配和释放通常比栈慢。
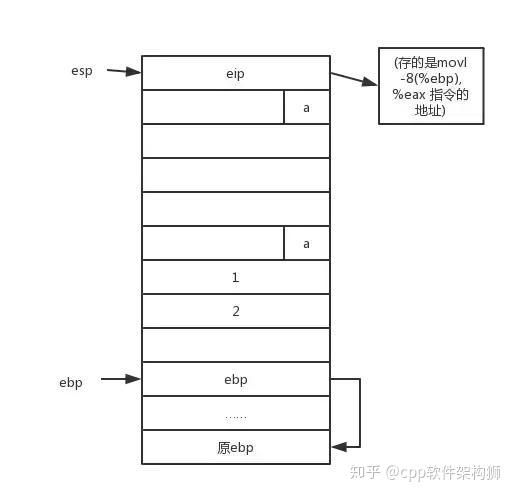
三、栈(Stack)
栈是一种后进先出(LIFO)的数据结构,它提供了一种快速的访问机制。在大多数编程语言中,栈被用来存储局部变量、函数调用的信息等。栈的内存管理相对简单,因为它遵循严格的先进后出原则。
特点:
- 快速访问:栈的访问速度非常快,因为它的操作通常在固定的内存空间内完成。
- 固定大小(局部):虽然全局变量的存储可能使用堆,但局部变量通常存储在栈中。
- 后进先出:栈的最后一个进入的元素总是第一个出来。
四、应用场景
- 堆的应用:在需要处理大量数据或未知数据量的场景中,如动态数组、字符串处理等,我们通常会使用堆来分配内存。此外,在面向对象编程中,对象通常存储在堆上,因为对象可能包含动态分配的成员,如指针或数组。
- 栈的应用:在函数调用、递归等场景中,栈被广泛使用。每个函数调用都会在栈上创建一个新的帧来存储局部变量和返回地址等信息。此外,在实现某些数据结构(如递归下降解析器)时,也会用到栈的概念。
五、总结
堆和栈是计算机内存管理的两个重要组成部分。它们各有特点,分别适用于不同的场景。理解并正确使用堆和栈,对于提高编程效率和程序性能具有重要意义。同时,熟悉它们在编程中的应用场景和原理,也是成为一名优秀程序员的重要一环。



















