

什么是过拟合
主机域名文章
2024-12-19 10:20
865
一、文章标题:什么是过拟合
二、文章内容
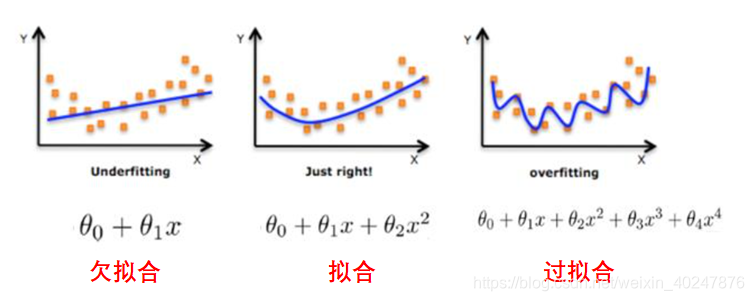
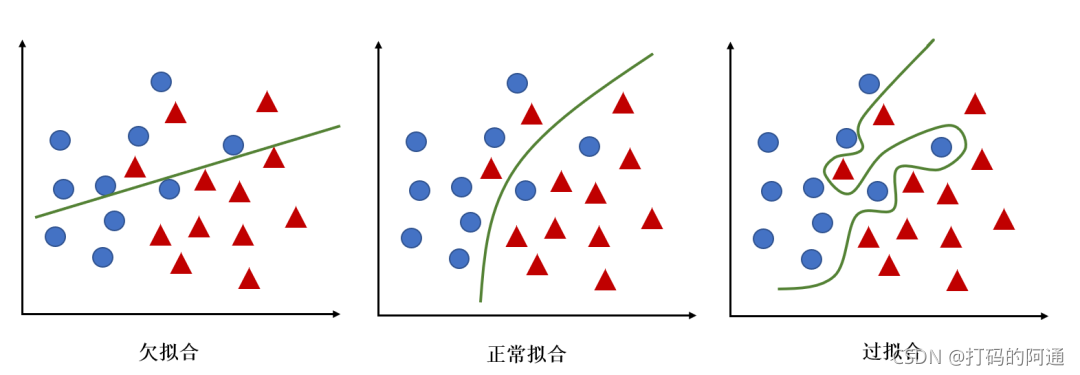
在机器学习和深度学习的领域中,过拟合是一个常见且重要的概念。过拟合是指模型在训练数据上表现优秀,但在未知数据上表现不佳的现象。简单来说,就是模型过于复杂,以至于它记住了训练数据中的噪声和无关细节,而无法泛化到新的数据。
1. 过拟合的定义
过拟合通常发生在模型复杂度过高,训练时间过长,或者训练数据集的样本量不足时。模型为了完美地拟合训练数据集的每一个特征和噪声,牺牲了其泛化能力。也就是说,它对于训练数据的适应能力太强,而对于未知数据的适应能力反而变弱了。
2. 过拟合的危害
过拟合的危害在于模型无法很好地泛化到新的数据上。在训练集上,模型可能表现出非常高的准确率,但在测试集或实际使用中,模型的性能却会大幅下降。这不仅会降低模型的预测能力,还可能导致模型的决策过程变得难以理解或预测。
3. 过拟合的原因
过拟合的原因往往涉及到模型复杂度过高、训练时间过长或训练数据集的不够全面。模型学习到了大量的特征信息,但是很多这些信息其实是无关紧要的,甚至是噪声信息。这就使得模型对于这些特征产生了过度依赖,而忽略了真正重要的信息。
4. 如何避免过拟合
为了避免过拟合,我们可以采取多种措施。首先,可以简化模型结构,降低其复杂度。其次,增加训练数据集的样本量,使得模型能够学习到更多的信息。此外,还可以使用交叉验证等技术来评估模型的泛化能力。同时,我们还可以使用一些正则化技术来控制模型的复杂度,防止其过度拟合训练数据。
总的来说,过拟合是机器学习和深度学习中一个重要的概念,我们需要对其进行充分的理解和掌握。通过合理的设计和调整模型结构、训练方法以及使用一些有效的技术手段,我们可以有效地避免过拟合的发生,提高模型的泛化能力和预测能力。
标签:
- 过拟合
- 机器学习
- 深度学习
- 模型复杂度
- 噪声
- 无关细节
- 泛化能力