

过拟合
主机域名文章
2024-12-14 10:05
615
文章标题:过拟合
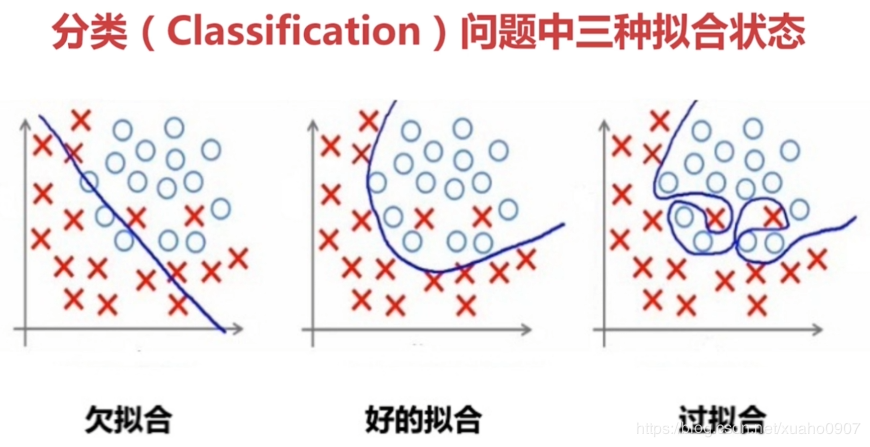
一、引言
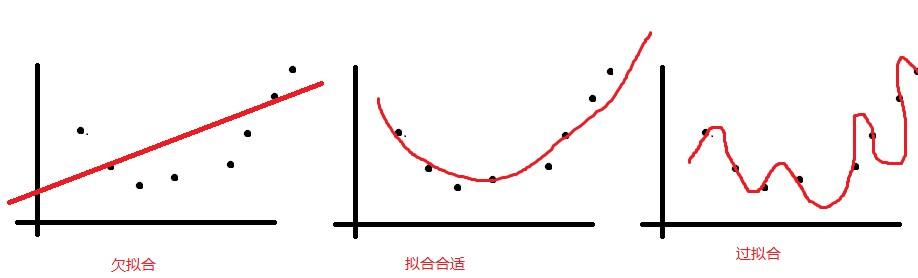
在机器学习和深度学习中,过拟合是一个常见的现象。它是指模型在训练数据上表现很好,但在未知的测试数据上表现不佳的现象。过拟合不仅会影响模型的泛化能力,还可能导致模型无法正确预测新的数据。因此,如何避免过拟合和提高模型的泛化能力成为了机器学习和深度学习领域的重要研究方向。
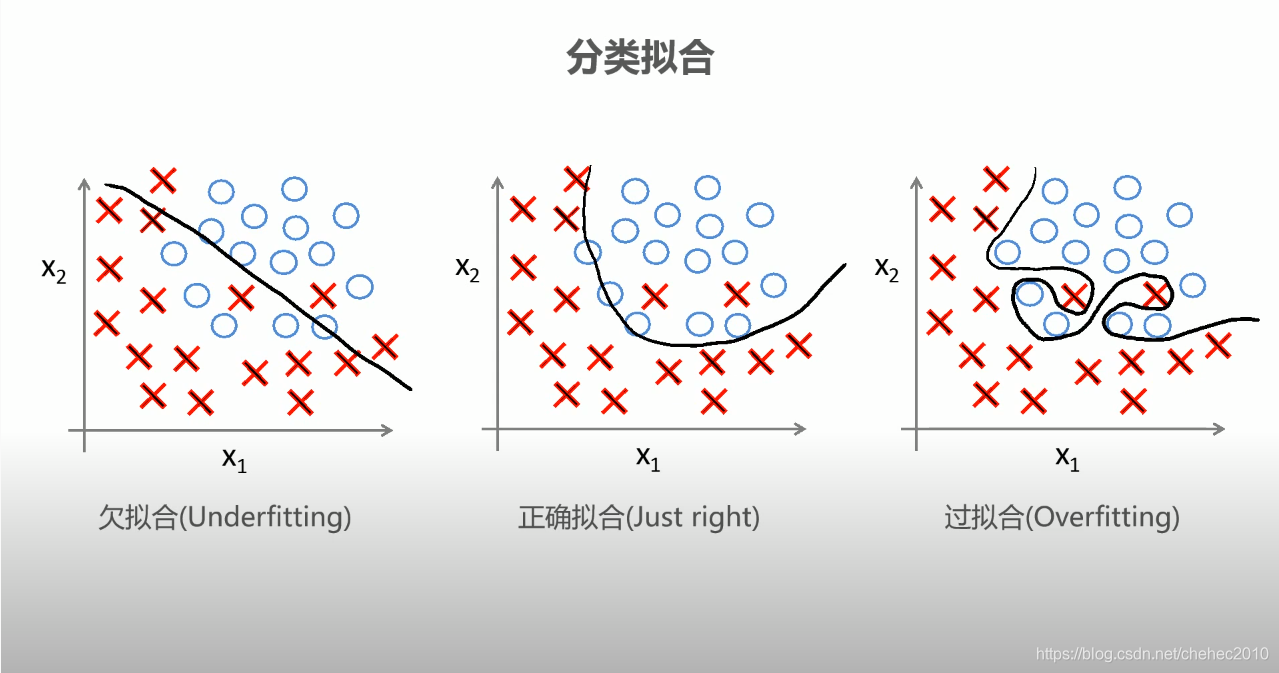
二、过拟合的原因
过拟合的原因有很多,其中最主要的原因是模型过于复杂。当模型过于复杂时,它会记住训练数据中的噪声和细节,而不是学习数据的真正规律。此外,数据集的不充分或过度处理、使用过于强大的模型以及评估方法的误导等都可能导致过拟合。
三、如何避免过拟合
-
简化模型:简化模型结构可以减少过拟合的风险。例如,在神经网络中,可以减少隐藏层的数量或神经元的数量来降低模型的复杂度。
-
增加数据集:增加数据集可以提供更多的信息来训练模型,从而减少过拟合的风险。可以通过数据增强等技术来增加数据集的规模和多样性。
-
交叉验证:交叉验证是一种常用的避免过拟合的方法。通过将数据集分成多个部分,每次使用一部分数据进行训练,另一部分数据进行验证,可以评估模型的泛化能力并调整模型参数。
-
引入正则化:正则化是一种通过添加约束条件来限制模型复杂度的方法。例如,L1正则化和L2正则化都可以用来减少模型的权重参数,从而避免过拟合。
四、总结
过拟合是机器学习和深度学习中常见的问题之一,它会影响模型的泛化能力和预测能力。为了避免过拟合,我们可以采取多种方法,如简化模型、增加数据集、交叉验证和引入正则化等。这些方法可以帮助我们选择更加适合的模型,提高模型的泛化能力和预测精度。未来随着机器学习和深度学习技术的发展,过拟合问题的解决方案将会更加多样化和完善。
标签:
- 过拟合
- 模型复杂度
- 数据集
- 交叉验证
- 正则化