

一、反爬虫概述
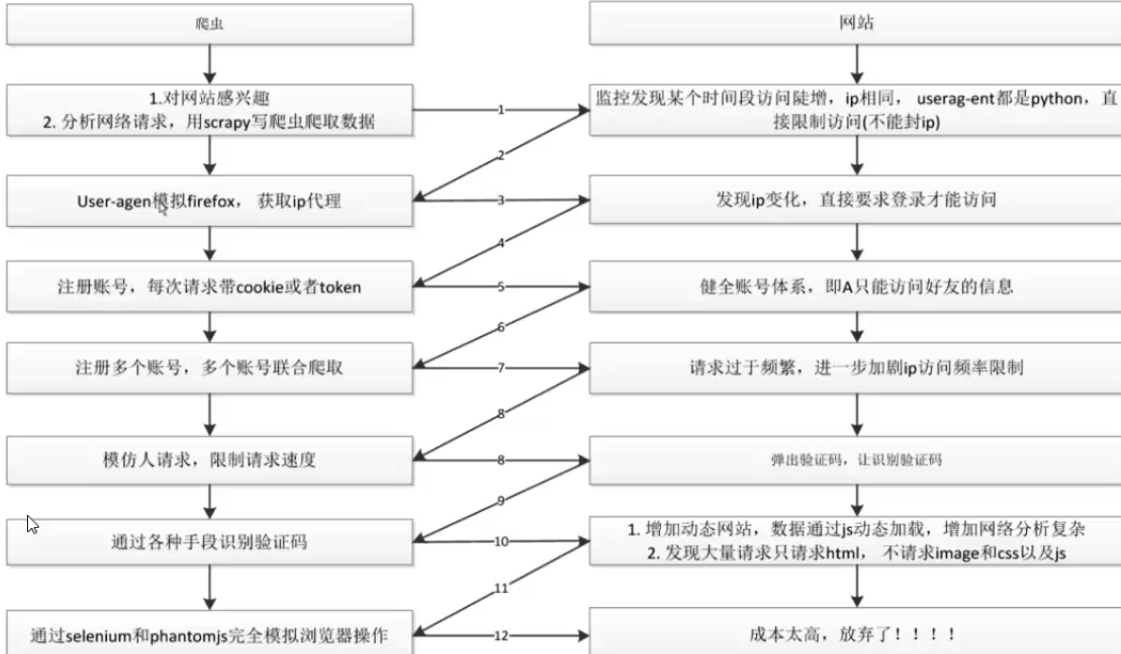
在互联网时代,数据已经成为了一种重要的资源。然而,随着网络爬虫技术的不断发展,数据安全问题也日益凸显。为了保护网站的数据安全,反爬虫技术应运而生。本文将介绍反爬虫的基本概念、原理及常见的反爬虫策略。

二、什么是反爬虫?

反爬虫,顾名思义,就是用来防止爬虫程序对网站数据进行非法抓取的技术手段。随着网络技术的不断发展,爬虫技术也日益成熟,但是,这也给网站的数据安全带来了威胁。因此,反爬虫技术应运而生,旨在保护网站数据的安全和隐私。
三、反爬虫的原理
反爬虫的原理主要是通过检测和识别爬虫程序的访问行为,从而对其进行限制或阻止。具体来说,反爬虫技术可以通过以下几个方面来识别和判断一个访问是否为爬虫程序:
-
请求频率:正常用户的访问频率是有限的,而爬虫程序通常会以极高的频率进行访问。因此,通过检测请求频率可以判断是否为爬虫程序。
-
请求头信息:正常用户访问时,会携带一些请求头信息,如浏览器标识、IP地址等。而爬虫程序通常不携带或伪造这些信息。因此,通过检测请求头信息可以判断一个访问是否为爬虫程序。
-
行为模式:正常用户的行为模式是多样化的,而爬虫程序的行为模式通常比较单一。例如,爬虫程序通常会按照一定的规律进行访问,如按照固定的URL顺序进行访问等。通过分析行为模式可以判断一个访问是否为爬虫程序。
四、常见的反爬虫策略
为了防止爬虫程序的非法抓取,网站通常会采取一些反爬虫策略。常见的反爬虫策略包括:
-
验证码验证:当网站检测到某个访问可能是爬虫程序时,会要求其进行验证码验证。只有通过验证的访问才能继续访问网站。
-
请求频率限制:对每个IP地址的访问频率进行限制,防止爬虫程序以极高的频率进行访问。
-
用户行为分析:通过分析用户的访问行为,如点击率、停留时间等,来判断一个访问是否为正常用户。对于异常的访问行为,可以采取限制或封禁等措施。
-
动态内容生成:对于敏感数据或重要数据,可以采用动态内容生成的方式来进行保护。即每次访问时生成不同的内容或结果,从而增加爬虫程序的抓取难度。
五、总结
总之,反爬虫技术是保护网站数据安全和隐私的重要手段之一。通过检测和识别爬虫程序的访问行为,可以有效地防止数据被非法抓取和利用。同时,网站也应该采取一些措施来提高自身的安全性和防护能力,如加强用户验证、定期更新和修复漏洞等。只有这样,才能确保网站数据的安全和稳定运行。
Label:
- 反爬虫
- 数据安全
- 网站保护
- 请求频率
- 行为模式