

Hive安装指南
一、概述
Hive是一个开源的、基于Hadoop的数据仓库工具,用于处理大规模数据集。本文将详细介绍如何安装和配置Hive,以便在Hadoop环境中使用。
二、安装准备
在开始安装之前,你需要确保已经安装了以下软件和工具:
- Java开发工具包(JDK):Hive需要Java环境,所以请确保你的系统已经安装了JDK。
- Hadoop:Hive是基于Hadoop的,所以你需要先安装并配置好Hadoop环境。
三、安装步骤
1. 下载Hive
首先,你需要从Apache官方网站下载最新版本的Hive。下载完成后,解压到适当的目录。
2. 配置Hive环境变量
在Linux系统中,你需要将Hive的bin目录添加到你的PATH环境变量中。这样你就可以在任何地方运行Hive命令。编辑你的~/.bashrc文件或~/.bash_profile文件(取决于你的系统),添加如下内容:
export HIVE_HOME=/path/to/your/hive/directory
export PATH=$PATH:$HIVE_HOME/bin保存文件后,运行source ~/.bashrc或source ~/.bash_profile来使更改生效。
3. 配置Hive Metastore和Driver服务
如果你需要运行复杂的查询,那么你需要启动Hive Metastore服务。这是通过hive的命令行界面启动的:hiveserver2或者你也可以用其他的服务器配置工具如foreman来管理它。同样地,为了进行管理或数据存储等操作,你还需要设置hive-driver。这两个服务的配置在hive-site.xml文件中完成。请根据你的环境配置这些参数。
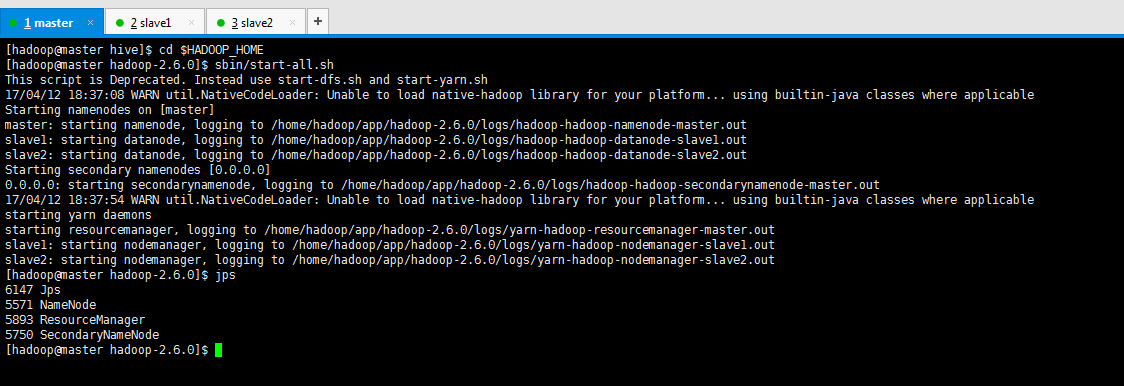
4. 启动Hadoop和Hive服务
首先启动Hadoop服务(例如:NameNode、DataNode等),然后启动Hive服务。如果你有Hadoop YARN作为资源管理器,你可能还需要启动这个服务。这可以通过相应的shell命令完成,或者在合适的服务管理器(如Cloudera Manager)中进行设置。在执行所有命令之后,你需要确保所有服务都在正常运行。你可以使用诸如jps命令或者其它类似的方法来验证你的Hadoop和Hive服务的状态。
四、测试安装
启动服务后,你可以通过在终端中输入hive命令来测试你的Hive是否已经成功安装和配置。如果一切正常,你应该能看到一个类似于“Welcome to Hive”的提示信息。这表明你已经成功安装并配置了Hive,并准备好使用它来处理和分析你的数据了。
五、结语
以上就是关于Hive的安装和配置的全部步骤。这是一个基本的指南,具体细节可能会根据你的环境和需求有所不同。如果你在安装过程中遇到任何问题,请参考官方文档或社区论坛以获取更多帮助。祝你在使用Hive的过程中一切顺利!
Label:
- 安装
- Hadoop
- 环境变量
- Metastore
- Hive服务
- 配置文件
- 测试安装