

爬虫是什么
主机域名文章
2024-12-15 11:30
569
爬虫是什么

在互联网时代,数据已经成为了宝贵的资源。而爬虫(也称为网络爬虫、网络蜘蛛、机器人等)就是用来自动从互联网上抓取数据的一种工具。它通过模拟人的浏览行为,从网站服务器上抓取并获取到网页内容,并对其进行相应的处理和分析。
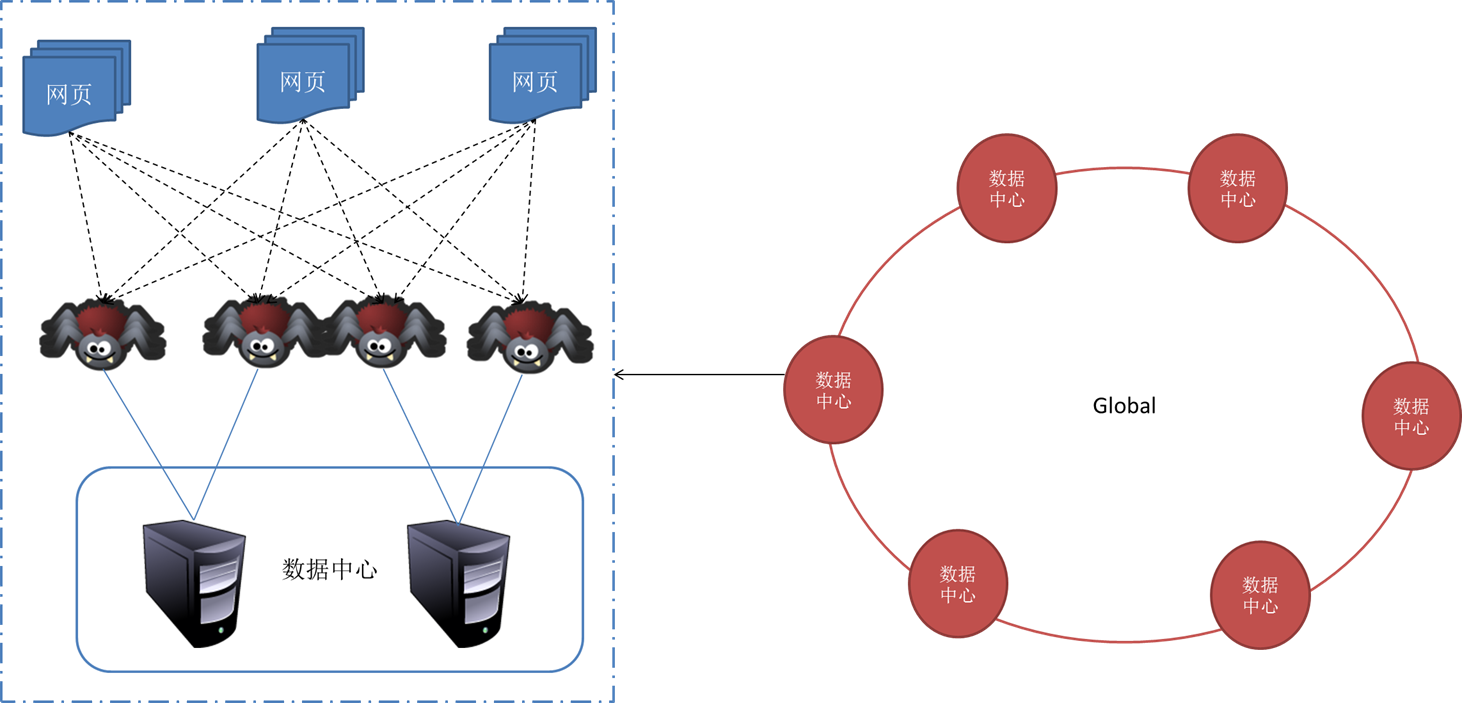
一、爬虫的基本原理

爬虫的工作原理其实并不复杂,主要包括以下几个步骤:
-
确定目标网站:根据需求确定需要抓取的网站和内容。
-
发送请求:爬虫会向目标网站发送一个请求,要求服务器返回网站的源代码。
-
解析页面:收到响应后,爬虫会对源代码进行解析,提取需要的信息,如文章标题、内容、图片等。
-
数据存储:将提取的数据存储到本地或数据库中,以供后续分析和使用。
二、爬虫的应用场景
爬虫在互联网上有着广泛的应用场景,包括但不限于以下几个方面:
-
数据采集:爬虫可以用于采集各种网站的数据,如新闻、文章、商品信息等。这些数据可以用于数据分析、数据挖掘等领域。
-
搜索引擎:搜索引擎的背后就是大量的爬虫在不断地抓取和索引互联网上的信息。通过爬虫技术,搜索引擎可以快速地获取网页内容并进行索引,提高搜索的准确性和效率。
-
舆情监测:爬虫可以用于监测互联网上的舆情信息,如社交媒体上的评论、论坛帖子等。这些信息对于企业或政府机构来说具有重要的参考价值。
-
网站监控:通过爬虫技术可以监控网站的访问情况和运行状态,及时发现和解决网站出现的问题。
三、总结
总的来说,爬虫是一种非常重要的互联网工具,它可以帮助我们快速地获取和处理互联网上的数据。但是,在使用爬虫的过程中也需要注意遵守相关的法律法规和道德规范,尊重网站的权益和隐私。同时,也需要不断学习和掌握新的技术和方法,以应对不断变化的互联网环境。
標籤:
- 爬虫
- 网络爬虫
- 数据采集
- 搜索引擎
- 互联网资源
- 隐私保护
- 自动化工具
- 网页解析