

kappa系数
主机域名文章
2024-12-04 15:00
1122
Kappa系数
在统计分析和机器学习中,Kappa系数(κ系数)是一种重要的评价工具,它主要用于评估两个数据集(例如模型预测结果与实际结果)之间的一致性程度。本文将介绍Kappa系数的定义、计算方法和应用场景。

一、Kappa系数的定义
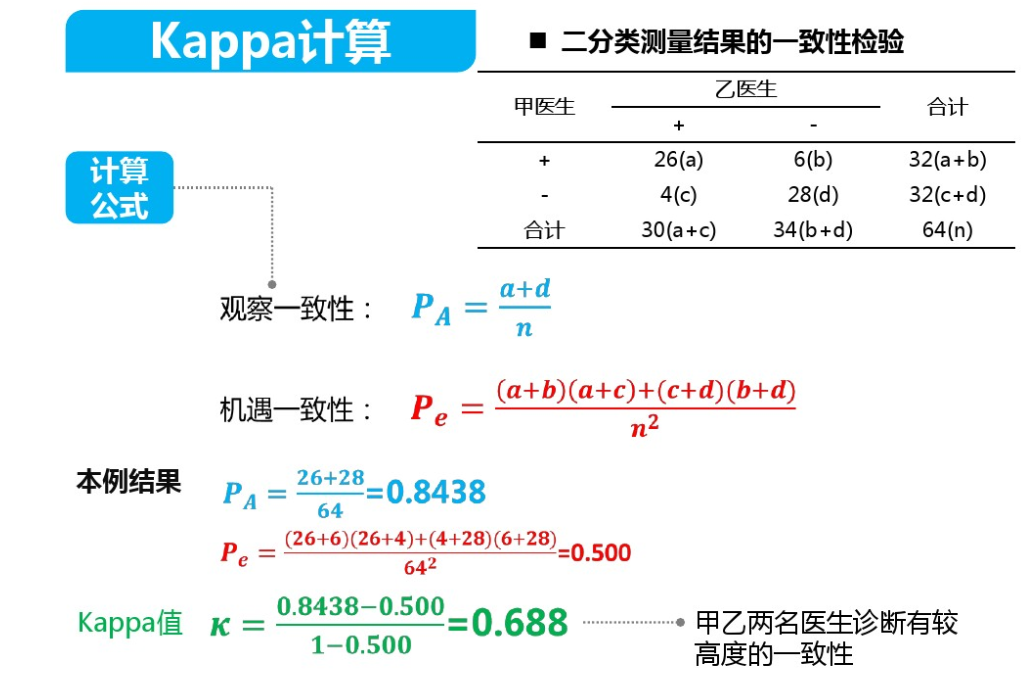
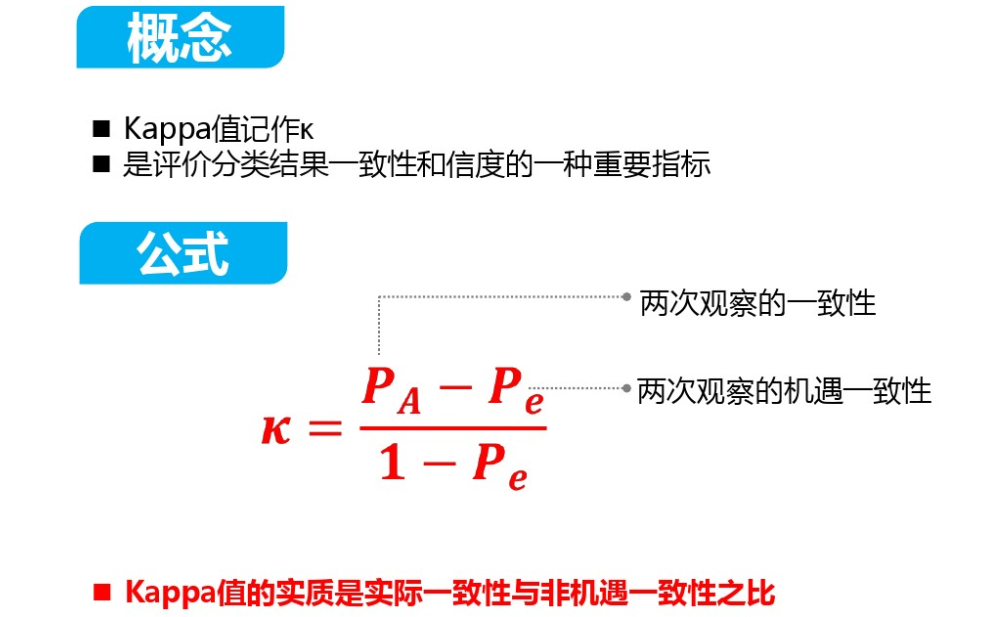
Kappa系数,又称Cohen's Kappa系数,是一种衡量分类问题中模型预测结果与实际结果之间一致性的统计量。它通过考虑随机误差的影响,来评估模型的实际表现。Kappa系数介于-1和1之间,其中1表示完全一致,0表示随机一致,负数则表示预测结果与实际结果有较大的不一致性。
二、Kappa系数的计算方法
计算Kappa系数通常需要以下几个步骤:
- 计算原始预测和实际结果的混淆矩阵。混淆矩阵是一个n×n的矩阵,其中n是类别数量。矩阵中的每个元素表示某一类别的实际样本被预测为另一类别的数量。
- 计算期望误差率(Expected Error Rate)。这是基于随机预测的误差率,也就是每个类别被随机预测的概率乘以实际该类别的数量。
- 计算实际误差率(Actual Error Rate),即根据混淆矩阵计算的误差率。
- 最后,使用公式计算Kappa系数:Kappa = (实际准确率 - 期望误差率) / (1 - 期望误差率)。
三、Kappa系数的应用场景
Kappa系数广泛应用于图像处理、自然语言处理、机器学习等领域。在图像分割、目标检测等任务中,Kappa系数可以用来评估算法的准确性和稳定性。在文本分类、情感分析等任务中,Kappa系数可以用来衡量模型预测结果与实际结果的一致性程度。此外,Kappa系数还可以用于比较不同模型或不同算法之间的性能差异。
总之,Kappa系数是一种重要的评价工具,它可以帮助我们更好地了解模型的实际表现和性能差异。在实际应用中,我们应该根据具体任务和需求选择合适的评价指标来评估模型的性能。
标签:
- Kappa系数
- 统计评价
- 一致性程度
- 混淆矩阵
- 机器学习应用
- 图像处理
- 自然语言处理