

一、引言

在数字化时代,数据处理变得至关重要。为了方便对大量数据进行有效管理和分析,数据必须先经过一定的转换和处理,其中一个重要的过程就是Tokenization(令牌化)。本篇文章将简要介绍什么是Tokenization以及其在各个领域的应用。

二、Tokenization 定义
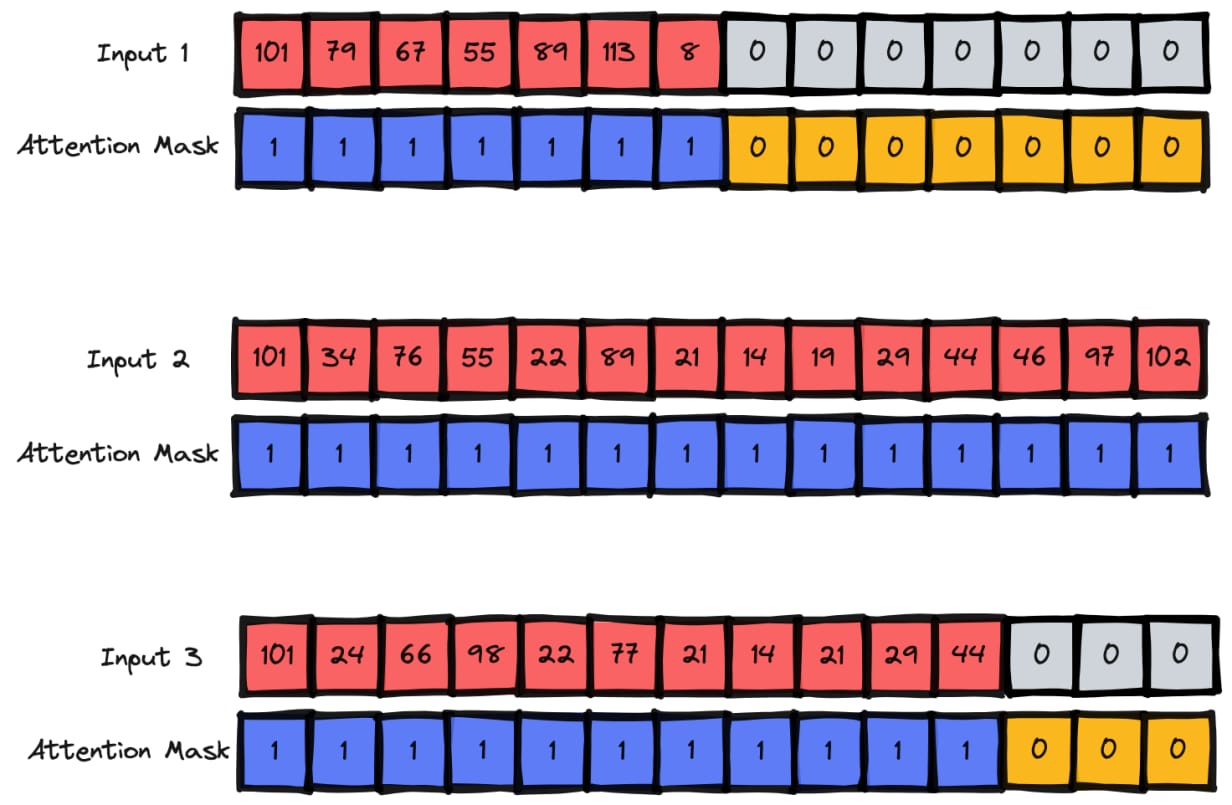
Tokenization 是一种数据预处理技术,主要作用是将文本数据转化为更便于分析和处理的形式。通过 Tokenization,我们可以将文本拆分成一个个的“令牌”(Tokens),这些令牌可以是单词、短语或字符等。这个过程是自然语言处理(NLP)和文本挖掘等领域的基石。
三、Tokenization 的步骤
-
分词(Tokenization): 这是将文本分割成一个个独立单元的过程。在中文文本中,通常是按照字或者词来进行分词。
-
过滤停用词: 在文本分词后,我们通常还需要过滤掉一些常用词,如“的”、“了”等没有实际意义的词语。
-
特征化: 对过滤后的词汇进行一些转化操作,比如转为词根形式(词形还原)、使用词性标签等。
-
生成词汇表(Vocabulary): 将所有的词汇整合到一个表中,方便后续操作和搜索。
四、Tokenization 的应用领域
-
自然语言处理(NLP): 用于解析和分析自然语言文本。如中文的文本翻译、自动摘要等都需要 Tokenization 的技术支持。
-
搜索引擎: 在搜索引擎中,Tokenization 是关键词提取的基础,是用户搜索请求与搜索引擎之间进行匹配的重要步骤。
-
机器学习: 在机器学习中,Tokenization 用于将文本数据转化为模型可以处理的数字格式,从而进行后续的分类、聚类等任务。
五、结论
总的来说,Tokenization 在我们的生活中扮演着非常重要的角色。无论是在自然语言处理、搜索引擎优化还是机器学习领域,Tokenization 都为数据分析和处理提供了强有力的技术支持。对于数据处理的专业人员来说,理解和掌握 Tokenization 技术是非常必要的。在未来的数字化世界中,我们将越来越依赖 Tokenization 来理解和处理文本数据。因此,继续深入研究和发展 Tokenization 技术对于提高数据处理的效率和准确性具有非常重要的作用。
希望以上内容可以满足您的需求,如有其他问题或需要进一步详细解释的内容,请随时告知我。
标签:
- Tokenization
- 数据预处理
- 令牌化
- 自然语言处理
- 文本转换
- 机器学习