

文章标题:SparkSQL 简述与实战
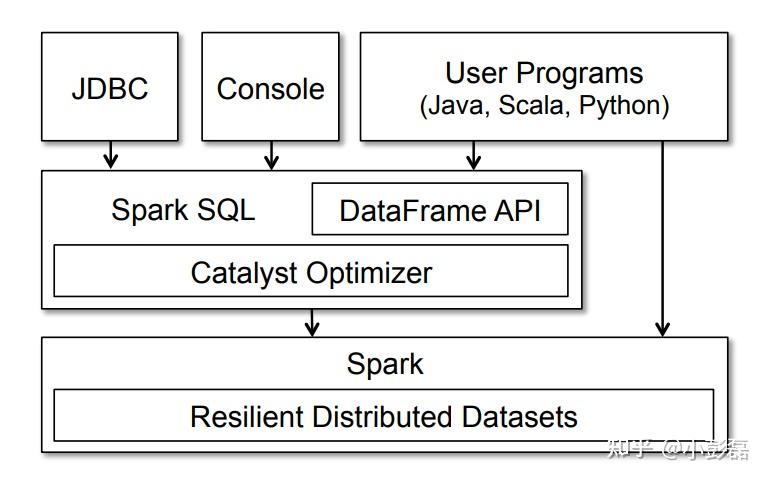
一、SparkSQL 简介

SparkSQL 是 Apache Spark 项目的一个模块,用于处理结构化数据。它提供了一种灵活的方式来处理大数据的 SQL 查询。使用 SparkSQL,用户可以通过 SQL 语句或者 DataFrame API 进行数据查询和操作,从而实现大数据的快速分析和处理。
二、SparkSQL 的主要特点
-
统一的数据处理引擎:SparkSQL 提供了统一的引擎来处理批处理和流处理,使得用户可以轻松地在同一套系统上处理不同类型的数据。
-
兼容多种数据源:SparkSQL 支持多种数据源,包括 HDFS、Hive、HBase、Kafka 等,使得用户可以方便地处理各种类型的数据。
-
高效性能:由于 Spark 的内存计算能力,SparkSQL 在处理大数据时具有很高的性能和效率。
-
灵活的 API:SparkSQL 提供了 SQL 语句和 DataFrame API 两种方式来操作数据,使得用户可以根据自己的需求选择合适的操作方式。
三、SparkSQL 的使用场景
-
数据仓库:SparkSQL 可以作为数据仓库的解决方案,用于处理大量的离线数据。
-
数据挖掘和分析:通过 SparkSQL,用户可以快速地查询和分析大数据,从而挖掘出有价值的信息。
-
流处理:利用 SparkSQL 的流处理能力,用户可以实时地处理数据流,从而快速地响应各种变化。
四、实战案例
下面以一个简单的 SparkSQL 查询为例,演示如何使用 SparkSQL 进行数据处理和分析。
假设我们有一个包含用户购买记录的表格,我们想要查询出购买次数最多的用户。我们可以使用 SQL 语句进行查询:
SELECT user_id, COUNT(*) AS purchase_count FROM purchase_table GROUP BY user_id ORDER BY purchase_count DESC LIMIT 1;
通过这个简单的查询,我们可以快速地得到购买次数最多的用户信息。当然,在实际应用中,我们还可以进行更复杂的查询和分析操作。
五、总结
SparkSQL 是一个强大的工具,它提供了统一的引擎来处理结构化数据,支持多种数据源和灵活的 API,使得用户可以方便地处理各种类型的数据。在大数据时代,SparkSQL 将成为数据处理和分析的重要工具之一。
标签:
- 关键词:SparkSQL
- ApacheSpark
- 结构化数据
- SQL查询
- DataFrameAPI
- 统一引擎
- 数据仓库
- 数据挖掘
- 流处理