正则化
标题:正则化的简介和应用
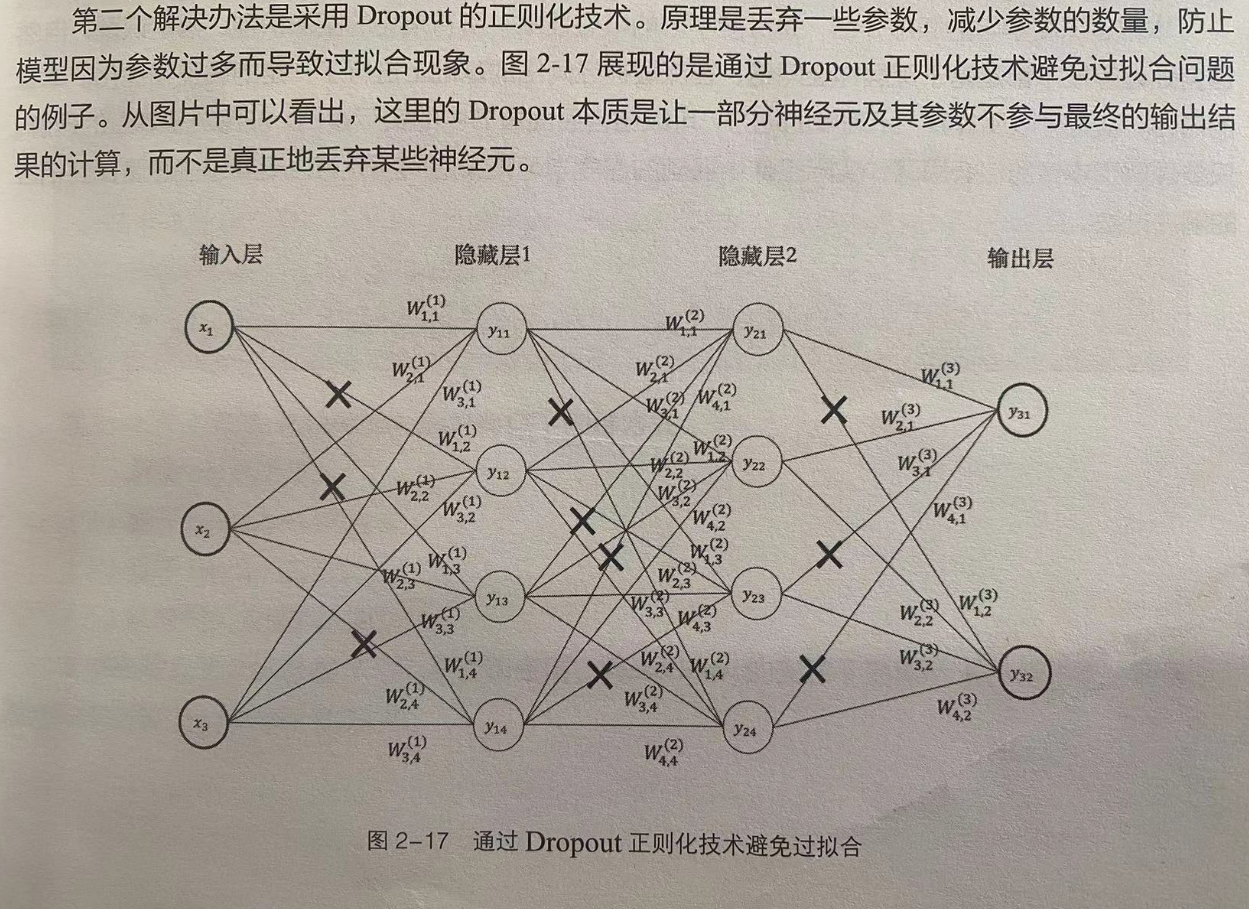
正则化是一种在机器学习和统计学习中广泛使用的技术,它可以帮助我们避免过拟合问题,同时也可以提高模型的泛化能力。在本文中,我们将对正则化进行详细的介绍,并探讨其在实际应用中的作用。
一、什么是正则化?
正则化是一种用于改进模型复杂性和过拟合的技术。简单来说,当我们构建一个机器学习模型时,我们需要确定哪些参数对预测结果至关重要。在某些情况下,我们的模型可能会过度关注一些不重要的特征,而忽略了重要的特征,这会导致过拟合现象。正则化通过在模型中添加额外的约束条件来避免这种情况的发生。
二、正则化的类型
-
L1正则化:L1正则化通过在损失函数中添加所有参数的绝对值之和来约束模型。由于L1正则化倾向于将一些参数置为零,因此它有助于特征选择和稀疏模型的构建。
-
L2正则化:L2正则化通过在损失函数中添加所有参数的平方和来约束模型。它通过惩罚大的权重值来避免过拟合,并有助于平滑模型的决策边界。
三、正则化的应用
-
防止过拟合:正则化是一种防止过拟合的有效方法。通过添加额外的约束条件,我们可以限制模型的复杂性并减少其在训练数据上的误差。这使得模型能够在未知数据上表现更好,因为它不会过度关注训练数据中的噪声和无关特征。
-
特征选择:在许多机器学习任务中,我们可能面临大量的特征选择问题。L1正则化可以帮助我们选择重要的特征并忽略不重要的特征,因为它倾向于将一些参数置为零。这有助于减少模型的复杂性和提高其泛化能力。
-
模型平滑:L2正则化可以使模型的决策边界更加平滑。这在处理高维数据时特别有用,因为平滑的决策边界可以减少模型对噪声的敏感性并提高其泛化能力。
四、总结
正则化是一种重要的机器学习和统计学习技术,它可以帮助我们避免过拟合问题并提高模型的泛化能力。通过添加额外的约束条件,我们可以控制模型的复杂性并使其更加稳定。无论是L1正则化还是L2正则化,它们都有各自的特点和适用场景。在实际应用中,我们可以根据具体任务和数据集选择合适的正则化方法来实现最佳效果。

