html解析
文章标题:HTML解析
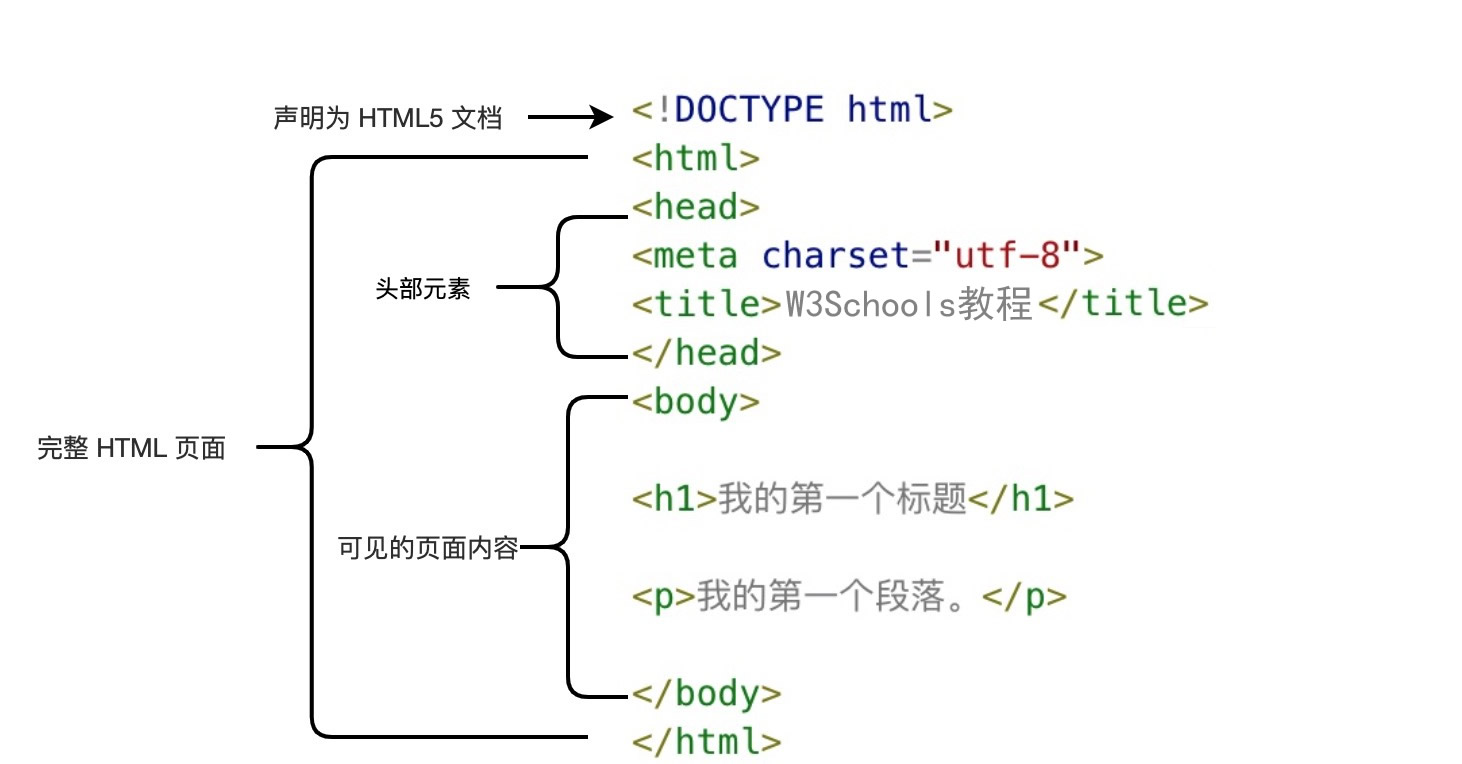
在互联网的世界里,HTML是一种非常基础的标记语言,它是网页的基础构成部分。而HTML解析则是指通过解析器对HTML文档进行解析的过程。在本文中,我们将深入探讨HTML解析的相关知识。

一、HTML解析的基本概念
HTML解析是指将HTML文档转化为计算机可以理解的结构化数据的过程。在这个过程中,解析器会读取HTML文档中的标签、属性等元素,并将它们解析成可以操作的数据结构。
二、HTML解析的过程
-
输入阶段:在这一阶段,HTML文档会被传递给解析器。这个阶段涉及到文件流的读取以及一些基础错误检测和报告机制。
-
构建阶段:在构建阶段,解析器会开始构建DOM树(文档对象模型树)。DOM树是HTML文档的抽象语法树,它描述了文档的结构和内容。
-
解析阶段:在解析阶段,解析器会根据DOM树对每个节点进行深入的处理。包括获取节点属性、查找子节点、获取节点的父子关系等。
-
输出阶段:在这一阶段,经过处理后的数据可以被程序以特定的格式进行输出或操作。比如,我们可以将DOM树以可视化的形式展示出来,或者通过JavaScript对DOM树进行操作来改变网页的显示效果。
三、HTML解析的应用场景
-
网页爬虫:在网页爬虫中,我们需要对网页进行解析以获取我们需要的信息。通过HTML解析技术,我们可以快速准确地从网页中提取出我们需要的数据。
-
网页开发:在网页开发过程中,我们经常需要使用HTML解析技术来动态地生成和修改网页内容。比如,我们可以通过JavaScript来操作DOM树来改变网页的布局和样式。
-
搜索引擎:搜索引擎需要从大量的网页中提取出有用的信息来建立索引。这就需要使用HTML解析技术来对网页进行解析和提取信息。
四、总结
HTML解析是互联网技术中非常重要的一环,它涉及到网页的生成、修改和提取等重要操作。随着互联网的不断发展,HTML解析技术的应用场景也将越来越广泛。因此,掌握HTML解析技术对于从事互联网相关工作的人来说是非常重要的。

