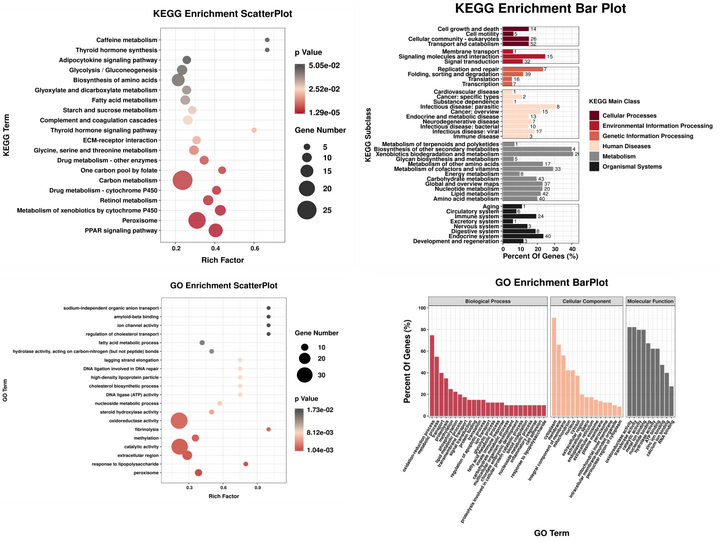
kegg富集分析
一、文章标题
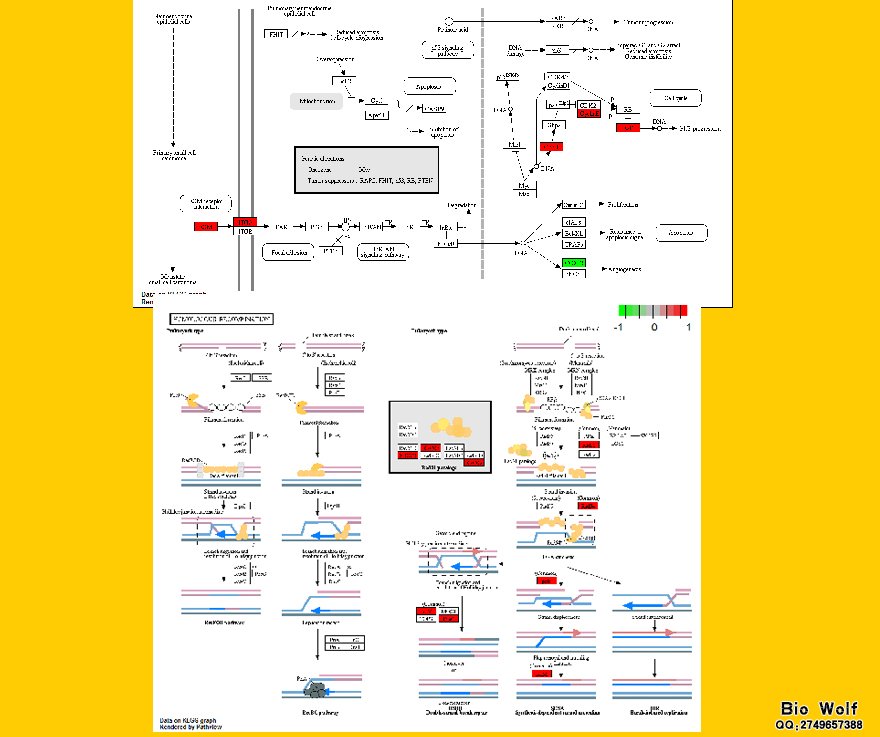
Kegg富集分析
二、文章内容
一、什么是Kegg富集分析?
Kegg富集分析是一种生物信息学中常用的方法,用于研究基因组学、代谢组学等领域的基因或代谢物数据。它通过比较实验数据与Kegg数据库中的数据,从而确定在某个特定生物过程或通路中,哪些基因或代谢物显著富集。这种分析方法有助于我们了解不同样本之间的差异,并揭示它们在生物体内的功能和作用机制。
二、Kegg富集分析的步骤
-
数据准备:首先需要收集实验数据,包括基因表达量、代谢物浓度等数据。同时,还需要下载Kegg数据库中的相关背景数据。
-
数据处理:将实验数据和背景数据进行预处理,包括数据清洗、标准化等步骤。这一步的目的是为了消除数据中的噪声和偏差,使数据更加可靠和准确。
-
映射Kegg数据库:将处理后的数据映射到Kegg数据库中,确定哪些基因或代谢物与某个特定生物过程或通路相关联。
-
富集分析:基于映射结果,计算每个生物过程或通路的富集得分和统计显著性水平。这一步是Kegg富集分析的核心步骤,它可以帮助我们确定哪些生物过程或通路在样本中显著富集。
-
结果解读:根据富集分析的结果,我们可以了解样本中哪些生物过程或通路发生了显著变化,并进一步探讨这些变化在生物体内的功能和作用机制。同时,还可以通过比较不同样本之间的结果,发现它们之间的差异和共同点。
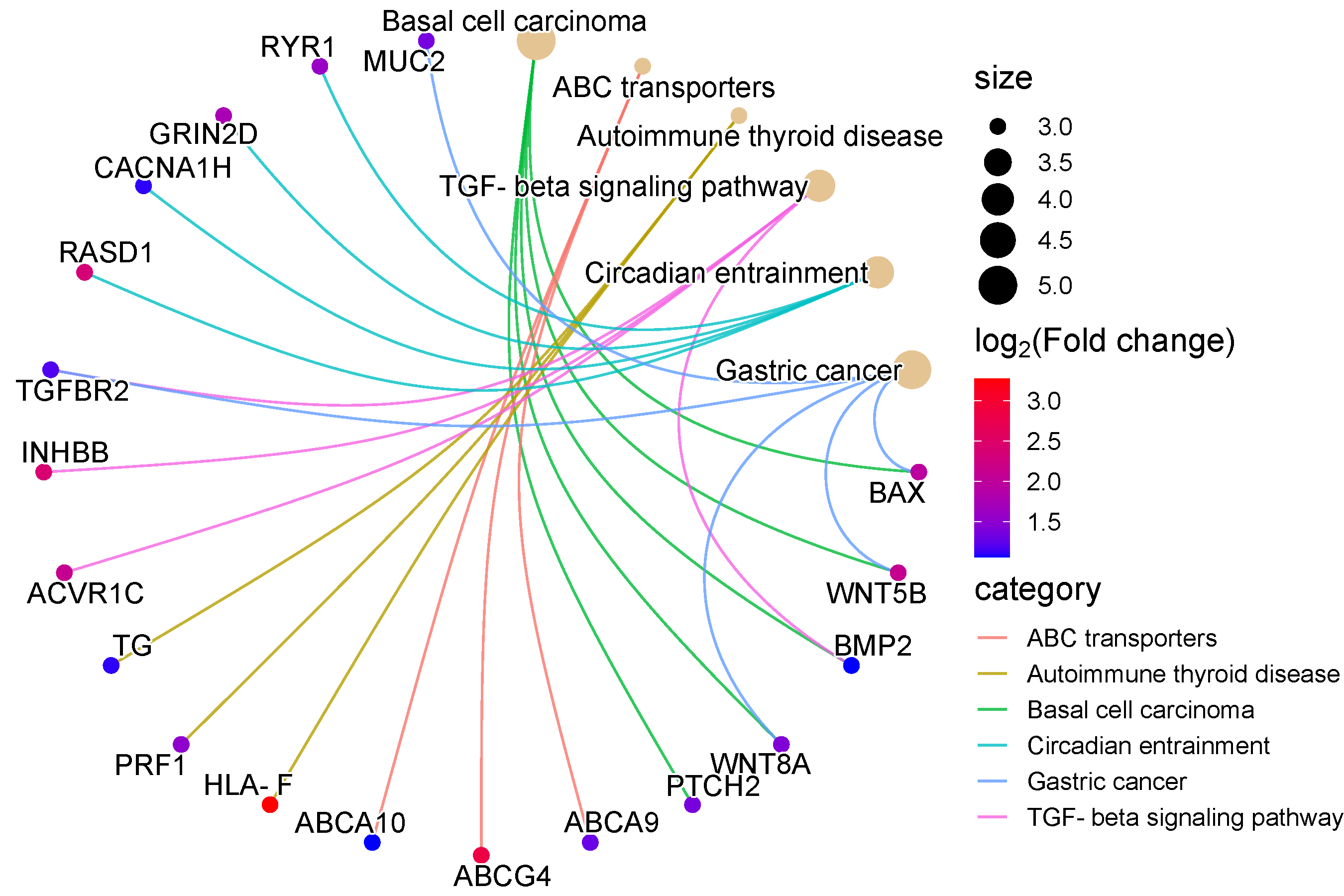
三、Kegg富集分析的应用
Kegg富集分析在生物信息学领域有着广泛的应用。它可以用于研究基因组学、代谢组学、疾病诊断和治疗等方面的研究。例如,在疾病诊断方面,可以通过Kegg富集分析找出与某种疾病相关的基因或代谢物,从而为疾病的早期诊断和治疗提供新的思路和方法。在药物研发方面,Kegg富集分析也可以帮助我们了解药物的作用机制和靶点,为新药的开发提供重要的参考信息。
总之,Kegg富集分析是一种重要的生物信息学分析方法,它可以帮助我们深入了解生物体内基因和代谢物的功能和作用机制,为疾病诊断和治疗提供新的思路和方法。随着生物信息学技术的不断发展,Kegg富集分析将在未来发挥更加重要的作用。

