Kafka
Markdown格式下的文章:
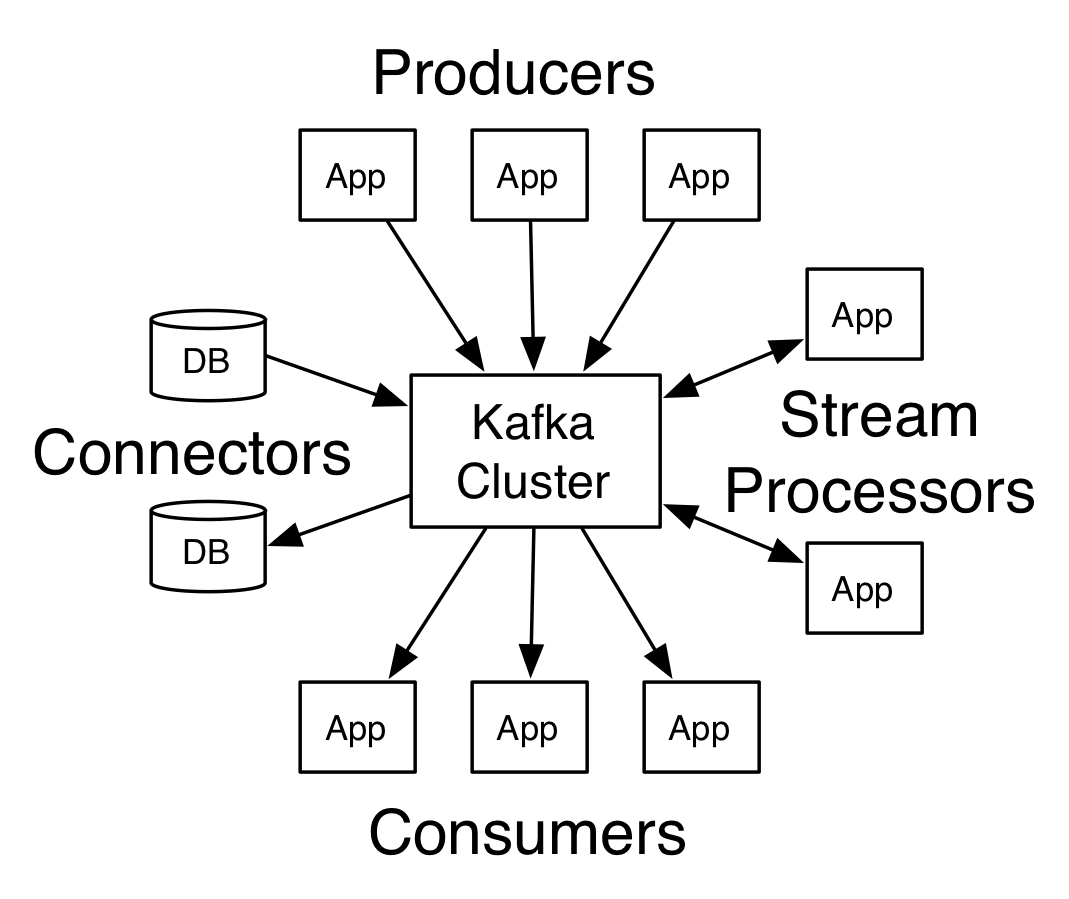
标题: Kafka

随着互联网和大数据技术的不断发展,消息队列作为中间件的重要组件之一,逐渐在众多业务场景中得到了广泛的应用。而Kafka作为一种分布式消息系统,已经成为现代大数据生态系统中不可或缺的一部分。
一、Kafka概述
Kafka是一种分布式、高吞吐量的流处理平台,可以用于构建实时数据流管道和应用程序。Kafka在大数据生态系统中具有非常高的地位,它可以作为大数据系统中的数据交换中心,提供消息队列和流处理功能。
二、Kafka的架构特点
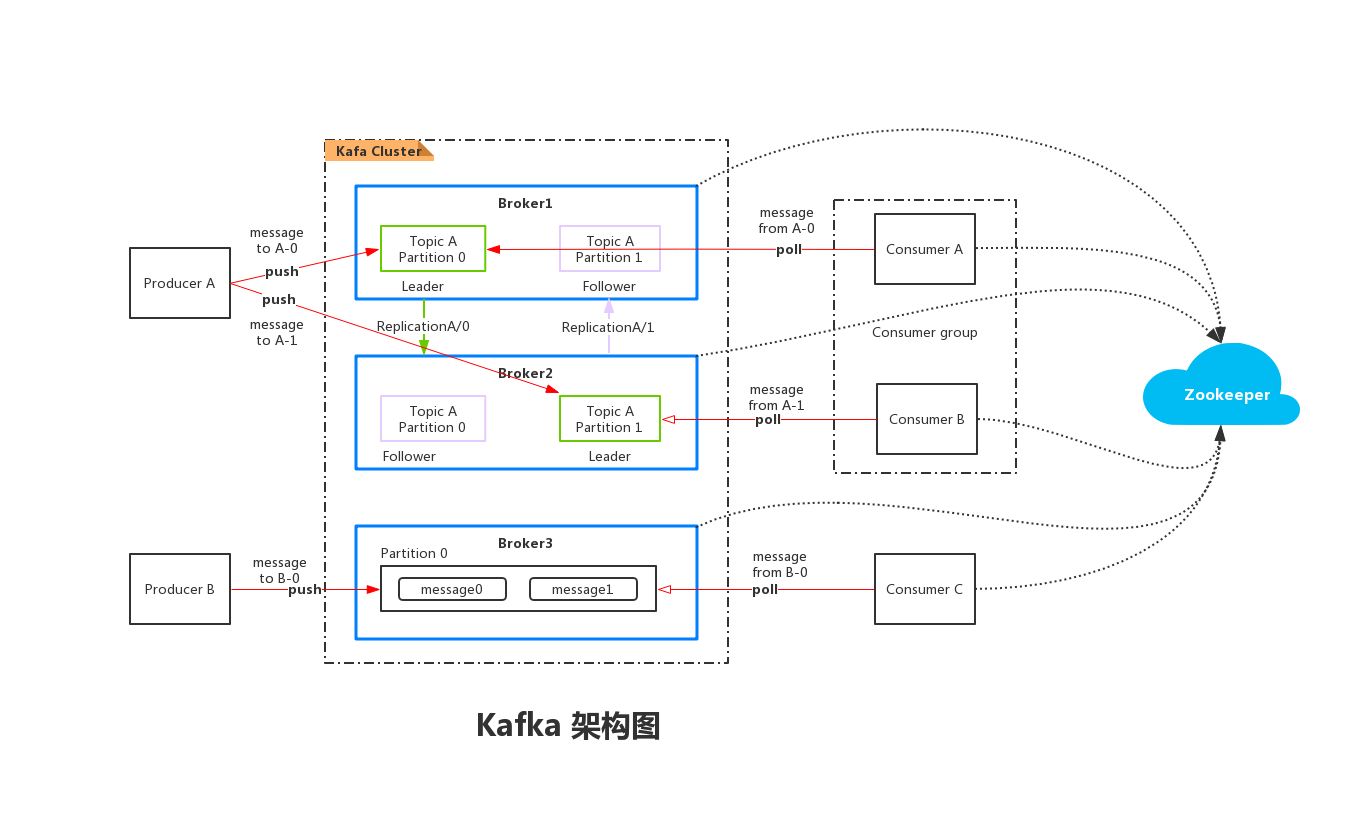
Kafka架构具有高可靠性、可扩展性、容错性等特点。其基于发布/订阅模式的消息队列架构,支持消息的持久化存储和高效传输。同时,Kafka还支持多副本备份和自动分区机制,保证了数据的高可靠性和高可用性。
三、Kafka的应用场景
-
实时数据流处理:Kafka可以用于构建实时数据流处理系统,如日志收集、事件追踪等场景。
-
消息队列:Kafka可以作为消息队列使用,支持各种异步通信场景,如用户注册、订单生成等。
-
大数据ETL:在大数据ETL(Extract, Transform, Load)过程中,Kafka可以用于收集、传输和处理大规模数据集。
四、Kafka的优势和挑战
优势:
-
高吞吐量:Kafka具有极高的吞吐量,可以处理大量的数据。
-
持久化存储:Kafka支持消息的持久化存储,保证了数据的可靠性。
-
社区支持:Kafka拥有庞大的社区支持,可以获得来自全球开发者的帮助和支持。
挑战:
-
配置复杂:Kafka的配置相对较为复杂,需要具备一定的技术基础才能进行配置和部署。
-
安全性问题:在处理敏感数据时,需要特别注意Kafka的安全性配置和加密措施。
五、总结
总之,Kafka作为一种分布式消息系统,在大数据生态系统中扮演着重要的角色。它具有高可靠性、高吞吐量、可扩展性强等特点,广泛应用于实时数据流处理、消息队列和大数据ETL等场景中。虽然在使用过程中可能会遇到一些挑战和问题,但通过合理的配置和部署,可以充分发挥其优势和价值。未来,随着大数据技术的不断发展和应用场景的不断拓展,Kafka的应用前景将更加广阔。

